Two-tower models for ranking problems
Summarizing recent papers and their disagreements

“We argue that such wishful thinking is unrealistic”
In an academic paper, them's fighting words. That's about as pointed as it gets. But who wrote that, and in response to whom?
To tell this story I will cover three papers from the last few years in the learning-to rank (LTR) literature, putting them in the context of each other. The papers contain models and evaluation methods that could be useful if you work in the ranking space.
It’s time for a tiny refresher on learning-to-rank. Many of our products have a ranked element to them, with Google Search being the canonical example. The key decision is what order to show search results. We could model which search results on Google are likely to get clicked. But that task is complicated by the fact that listings at more prominent positions (at the top) are more likely to get clicked than results much further down, even if they aren’t more relevant. When we model, our existing data reflects (is “biased” by) this fact that some items were heavily advantaged relative to others. There is a massive literature on this problem. I’ve covered a little bit of it in two previous posts, The position bias problem, with code and A simple and robust approach to measuring position bias. The first of those particularly leads naturally into this post.
Position-bias Aware Learning framework (PAL)
One obvious approach is to use position as a feature in the model, such that the model can attribute the ranking bias to the position feature. Ideally the model learns that relevance factors like ratings are important, and also that position was important too. Then when we rank (at “inference” time), to compare items we can use a constant placeholder for every item’s position. This method is simple but has a host of drawbacks (of which I’ll touch on later on, and my past post covered in more detail), and isn’t popular in the literature.
A modern variation on this approach, in an era of neural network popularity, is to use a two tower neural network where one tower uses unbiased features, while the other uses biased or endogenous features like position. We multiply the heads of those two towers together for our final probability, evaluated with log loss against clicks in our final layer. The two towers are jointly optimized as one neural network model. One tower is supposed to learn P(Examination | Position) and the other P(Click | Examination), such that when they are multiplied together they give P(Click | Position). This relationship is the “separability hypothesis” [1]. Other than the two tower structure to the network that splits layers into two separate dense structures, this is a standard dense feed forward neural network for probability prediction.
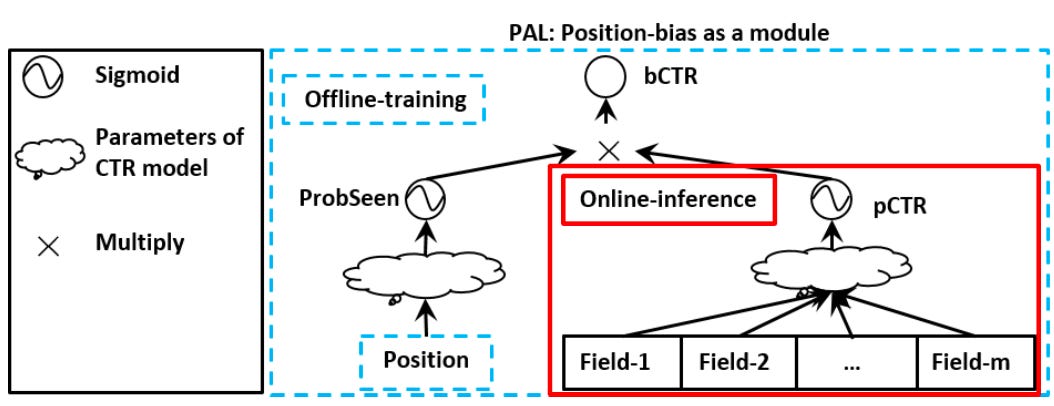
That’s what PAL is. Its authors at Huawei call the towers “modules”, and they explain the approach as:
The idea of PAL is based on the assumption that the probability of an item is clicked by a user depends on two factors: a) the probability that the item is seen by the user and b) the probability that the user clicks on the item, given that the item has been seen by the user. Each factor is modeled as a module in PAL and the product of the outputs of these two modules is the probability that an item is clicked by a user.
The PAL authors contrast this against a neural network with the same features and loss function, but without the two-tower isolation. While PAL’s offline results aren’t better than the non-isolated network, in an A/B experiment PAL did much better.
There are many applied ranking problems that use this technique or variations with the same principles. I highlight the PAL paper because it is the canonical paper that described the specific two-tower method and gave it a punchy name. One downside of picking a punchy name is becoming a target for future writers, and I’ll cover two papers that have a one-two punch of their own.
The jab: A first critique
In Revisiting Two-tower Models for Unbiased Learning to Rank, six researchers at Google critique PAL and related methods [3]. Some of these authors are among the most accomplished and prolific researchers in the learning-to-rank literature.
In this paper the Google researchers acknowledge that the PAL method could be better than other general models with position as a feature, because PAL “introduces inductive biases to allow more efficient use of limited observational logs and better generalization during deployment than single-tower architecture that may learn spurious correlations between relevance predictions and biases”. The “inductive bias” is that the method only allows position factors and relevance factors to interact at a final stage, rather than letting them heavily interact throughout the model. Model parameters aren’t used for early interactions; the “efficient” part is that the model could be smaller or could (alternatively) learn more relevance relationships at a given size, and not falsely learn relationships between position and relevance that fit the data but aren’t truly causal (“spurious correlations”).
This paper’s critique is that “the first-order multiplication between two towers may be too limited to model real-world datasets”—that the separability hypothesis and a multiplicative relationship between examination probability and click probability might not be true.
While the separability hypothesis and its corresponding model, the position-based propensity model (PBM), are quite established in the literature, “these limitations are largely neglected in the research community, since it is a common practice to study unbiased learning algorithms after generating synthetic data by following such assumptions”. If we generate data that fits the PBM and then evaluate a PBM-tailored method against that data, the method is likely to succeed. These authors decide to test against synthetic data that reflect different user behaviors.
The authors propose models for when position and other features are less separable. They propose two types of methods. One is a non-separable model that is jointly optimized using expectations-maximization (EM). I don’t want to go into this in too much detail; see a prior post about a earlier EM paper from some of these authors. The second method uses towers where the tops of each are vectors rather than single values, using the “dot product interactions of embeddings to niche the complex interaction beyond the additive models”.12 This second method is conceptually much like the two-tower approach of PAL, just with more expressiveness where the towers merge.
They evaluate on two types of data. The first is synthetic user behavior, such as users following a PBM model, or users clicking randomly, or users having no position bias, or users only caring about position and not relevance. The second is on rankings from Chrome Web Store (CWS), evaluated offline with NDCG.
On the synthetic data, biased baselines that don’t have any position features do poorly across all mixtures of user behavior. PAL beats the biased baseline and the new methods on some specifications, while the new methods do well on some others. This comparison effectively illustrates how different types of user behavior affect which approach will do better.

While that table shows the new methods doing better on three out of five comparisons, it’s a bit misleading to count victories like that. The rows shouldn’t all be treated equally. The “0:0:0:1” comparison is where users follow a PBM behavior, and that’s probably the most relevant of the rows. There’s a reason that a long literature has often preferred the PBM as a realistic model, since earlier papers described how it is an effective heuristic for user behavior. On the contrary, the “0:1:1:0” line, for example, has 50% of users clicking by position without caring at all about which document is ranked where, and 50% caring about document quality but not caring about position at all. Surely that isn’t a more realistic behavior heuristic than the PBM.
The CWS data is reassuring on that point, because its user behavior model is the actual combination of behaviors from real users. On this data, not only do the new methods do better than PAL, but PAL sometimes does even worse than the biased baseline.

This doesn’t entirely surprise me, as I have previously explained how position-in-the-model models can occasionally be worse than ignore-position-entirely models. Point to this rebuttal paper.
Altogether, I find it fitting to call this paper a “jab” because its critique is valid but far from a knock-out punch.3 The synthetic data evaluation had mixed results. Chrome Web Store is a good data point, but it is one particular search product, and I’m not sure how representative it is. Why didn’t the (Google-employed) authors show us data on Google Search, Gmail, or Google Drive?4 They also don’t include an A/B test here. On the contrary, the two-tower literature, such as the aforementioned PAL paper and the Airbnb and YouTube papers called out in this rebuttal, use A/B tests to show that PAL did well for them [2, 4, 5]. Those A/B tests weren’t exhaustive and didn’t compare against many methods methods, and certainly not against the yet-to-be-invented methods of the rebuttal paper, but they at least show some amount of real-world success. The core critique of this paper is that the PBM might be too restrictive of a model for actual user behavior. Critiquing the PAL paper on the separability hypothesis, when the PBM has grounding dating back to eye-tracking studies and a decade of empirical applications, is far from repudiating the method. Especially with only a single real-world dataset to establish the point, and only on offline data.
Regardless, the paper is still a valid critique and serves an important purpose of questioning our dominant assumptions.
The cross: A second critique
Very recently, a year after the last paper, the same authors wrote another critique with a seventh Googler and now a new external lead author, Yunan Zhang from UIUC.5 This one is titled Towards Disentangling Relevance and Bias in Unbiased Learning to Rank. This critique is much more stinging. Rather than argue that the specification is a poor choice to model user behavior, the authors now argue that the PAL approach doesn’t fundamentally address the bias from ranking. They state this eloquently in many ways. In a very expressive example, they explain:
Consider the extreme case where the logged positions were from a perfect relevance model (please note this is only an example for intuition), then the observation tower can potentially absorb all relevance information during two-tower model learning and explain the clicks perfectly. The resulting relevance tower, on the other hand, can be completely random and thus useless.
In effect, “bias features and relevance features are both correlated with true relevance, which violates the independence assumption of observation and relevance signals” [6].
The PAL paper had said “the influence of position-bias and user preference is learned implicitly and respectively” [2]. The second rebuttal rephrases this as “ideally, the factorization will automatically let the two-tower models learn relevance and biases into their respective towers”. Yet the optimization method doesn’t actually enforce such a split into respective towers. PAL is still just fitting the data, minimizing log loss and picking parameters for each tower accordingly. Expecting this to result in one tower that perfectly isolates the impact of position, without over-attributing to position because of positional correlation with relevance, is the wishful thinking so strenuously critiqued by Zhang et al. This is the downfall of many position-in-the-model approaches, and it’s the same fundamental problem whether we’re using a logistic regression or a two-tower neural network. Zhang et al. even show empirically that “the more correlated the bias and relevance are, the less effective the relevance tower is”.
The modeling methods from the last paper are gone too, replaced by a new method. The old methods aren’t measured here, but if we contrast between the papers we can see this new method improves on NDCG on the synthetic data.6 This time the authors hammer home the point with an A/B test on Chrome Web Store. Not only does their new method do better than PAL, but so does an entirely biased model that doesn’t even include position factors.
In a way this is not only a rebuttal of PAL, but a philosophical rebuttal of their own prior paper, which is open to some of the same critiques as PAL and had labelled PAL as “sound in theory by following the Position Based Model (PBM) click model to model user behaviors” [3]. Not only does the new paper not critique the PBM, but the authors even generate synthetic clicks using the PBM exclusively, a practice they lightly critiqued in the prior paper.
What is this exciting new method that outperforms PAL? They call it GradRev, applying the Gradient Reversal technique. They start with a two-tower architecture, but in the backpropagation step they add additional loss to the position tower based on how well it predicts clicks.

At first I expected the goal would be to make the position tower orthogonal to the relevance tower, especially since the authors described several adversarial labels including how well the position tower predicted the relevance tower outcomes. But the authors eventually chose clicks as the adversarial label for their A/B test specification. Clicks are the label of the model as a whole, and the position tower does need to end up with some predictive power for it.
That choice, plus the authors evidence that the model works with several different adversarial labels, makes me interpret this method as working because it penalizes the position tower in general. This will help counteract the tendency of models to attribute too much influence to position, or in their words, “we want to unlearn the relevance information captured by the observation tower, thus pushing more relevance information to the relevance tower during learning”.
Curiosity and cautious optimism
That’s a little summary of some recent papers in the LTR literature. I’m excited by the GradRev method, since it had good results and is fairly simple to implement.
I would like to resolve some open questions on details that aren’t well-described in the paper.
The authors use a tunable hyperparameter for how much to penalize the position tower. The paper has no theoretical grounding on how much or little to penalize the position tower. I’m curious how this performed across the domain for that hyperparameter. I wonder how sensitive or consistent results are with respect to this parameter. I don’t even know which value they ended up using.
It’s unclear to me exactly how they handle position when using the model for online ranking. At first I assumed they followed the PAL method of only using the relevance tower during online inference. But Figure 3 refers to “Predicted Logged Position”, which the figure clearly emphasizes it used in “Serving”. It makes sense to me in offline analysis (“logged sessions”) but has an unclear implication for online serving.
Given the uncertainty with any new method, I would like to see it tested on more products than Chrome Web Store, especially if those tests came from other companies and with public code.
I'll keep an eye on future developments. The GradRev method in general is a bit of a hack, but it’s the type of hack that I adore: simple and practical. “Simplicity is SOTA”, quite literally.
I enjoyed all of these papers, I learned from them, and I believe they’ve made important contributions to the literature with the potential for lasting impact.
[1] Dupret, G., & Piwowarski, B. (2008). A user browsing model to predict search engine click data from past observations. Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.
[2] Guo, H., Yu, J., Liu, Q., Tang, R., & Zhang, Y. (2019). PAL: a position-bias aware learning framework for CTR prediction in live recommender systems. Proceedings of the 13th ACM Conference on Recommender Systems.
[3] Yan, L., Qin, Z., Zhuang, H., Wang, X., Bendersky, M., & Najork, M. (2022). Revisiting Two-tower Models for Unbiased Learning to Rank. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval.
[4] Haldar, M., Abdool, M., Ramanathan, P., Sax, T., Zhang, L., Mansawala, A., Yang, S., Turnbull, B.C., & Liao, J. (2020). Improving Deep Learning for Airbnb Search. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
[5] Zhao, Z., Hong, L., Wei, L., Chen, J., Nath, A., Andrews, S., Kumthekar, A., Sathiamoorthy, M., Yi, X., & Chi, E.H. (2019). Recommending what video to watch next: a multitask ranking system. Proceedings of the 13th ACM Conference on Recommender Systems.
[6] Zhang, Y., Yan, L., Qin, Z., Zhuang, H., Shen, J., Wang, X., Bendersky, M., & Najork, M. (2022). Towards Disentangling Relevance and Bias in Unbiased Learning to Rank. ArXiv, abs/2212.13937.
[7] Demsyn-Jones, R. (2022). Measurement and applications of position bias in a marketplace search engine. ArXiv, abs/2206.11720.
I had to quote that line, because it's so rare to see the verb use of “niche”.
In my geekiness about the taxonomy of embeddings (see an earlier post, What is an embedding, anyways?), I'm curious whether the authors call these vectors “embeddings” because they have isolated inputs and clear interpretations (on position and relevance, respectively), or because of the dot product between them, or because of the combination of both. Consider that the single-valued towers of PAL also are isolated to position and relevance and also are multiplied together, yet implicitly these authors don't consider those to be embeddings. So maybe embeddings have to be multi-valued. Seems that multiplying two numbers doesn't mean the two numbers are embeddings, but multiplying two vectors means they are.
Setting aside that we do see the rare knockout jab in pro fights.
They do have other papers with data from these products.
This is an awesome paper in general, but especially impressive from someone early in their research career.
Surely the authors wouldn't change their dataset on us to invalidate this comparison, right?