

The rise of GELU
Looking back at how GPT and other modern models ended up using GELU, and reviewing whether we have much substantial evidence for using GELU.

Like others who have observed the incredible success of ChatGPT, I’ve recently put some time into building and understanding large language model (LLM) architectures. Instead of sharing my thoughts on some of the well-discussed (and, truly, the most exciting) elements of ChatGPT, I want to diverge and cover the GELU activation function. Its use in GPT models has sent me down a bit of a rabbit hole on the activation function literature.
Brief refresher: in a typical neural network, we have layers where we multiply the inputs to the layer with learned weights, then add those weighted inputs together, plus a learned offset (“bias”), and feed the result through some predetermined function. By learning the weights we learn a function of those inputs. That gives you one output neuron in the next layer. We usually have many such output neurons, each with their own set of learned weights. The next layer then repeats the process, now using the output from the previous functions as inputs to the next learned functions. With enough of these, we can learn very complex nonlinear functions that let us classify images, translate text, or any of a host of other problems where ML has human-level performance.
This pattern is called a “fully-connected” (or “dense”) layer, and while it’s far from the only type of layer in neural networks, it’s a key building block. Traditionally this is drawn using a convention of lines representing weights.

The weights are what our models learn, what makes them unique and different from manually-defined functions. But the predetermined function through which we pass the resulting dot-product is important too. We call that function an activation function, and usually we use the same activation function throughout a model, using it as many times as we have output neurons for all of our dense layers combined. If we didn’t have activation functions then we wouldn’t have any non-linearity in our models, drastically impacting the expressiveness of ML. This matters. Yet the activation function is usually not learned in model fitting, but rather it is typically picked by researchers as part of their architecture design, often by following precedents in the literature.
Pieces of the history of activation functions
There was a period when the logistic function (referred to as “sigmoid” in the neural network literature) and the hyperbolic tangent (tanh) function were common activation functions. Both functions nearly plateau at their positive and negative extremes, with a smooth transition in between. The change in slope in their distributions creates the potential for non-linear relationships. However, the flatlining led to extremely small gradients, creating the vanishing gradient problem with floating point calculations. That was one of the major limitations preventing scaling neural networks to large architectures.

The sigmoid and tanh activation functions were superseded by a simpler function, ReLU. The output of ReLU is the same as its input, unless the input is below 0, in which case the ReLU output is 0. Despite the non-differentiability of the kink at 0, ReLU rapidly dominated neural networks. ReLU can be computed quickly and simply, and furthermore its use typically leads to faster convergence and higher accuracy [3]. ReLU only flatlines in one direction instead of two. Modifications to ReLU to prevent flatlining on the left side of the distribution have had some success, but none are so broadly successful as ReLU.
But now the world’s most famous model, ChatGPT, uses GELU instead of ReLU.1 As do many others. Papers With Code has a nice comparison of activation functions in papers over recent years, and GELU is now neck-and-neck with ReLU as the most common activation function. I would wager that more state-of-the-art (SOTA) papers use GELU, evidenced at a minimum by the GPT series of models.
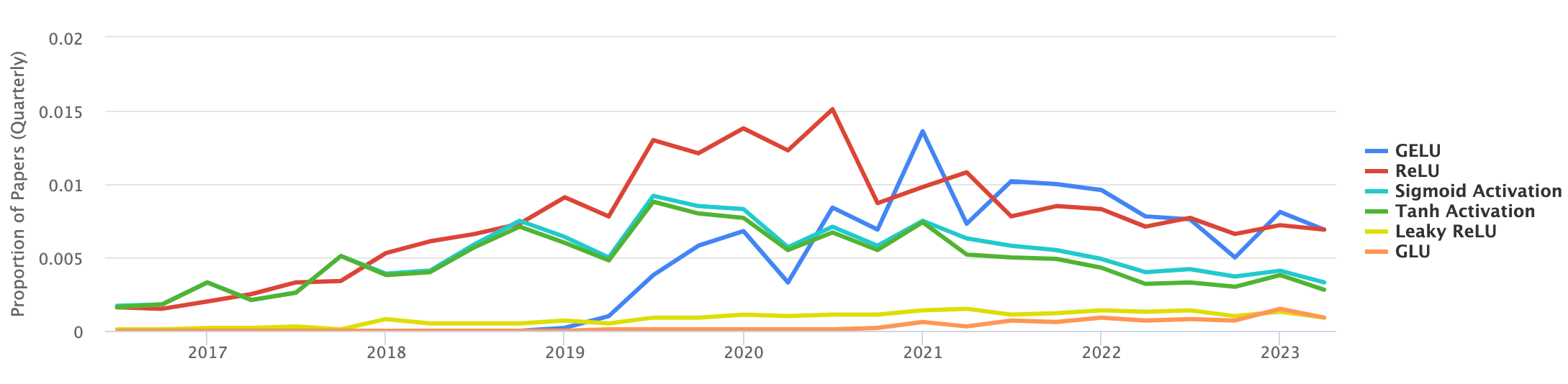
What changed? What is GELU and why did it boom?
GELU
The GELU paper, by Hendryks and Gimpel, is a clear and short read. GELU is inspired by how the dropout method uses probabilistic zeroing of neurons. The authors describe how we could treat the input to an activation function as a draw from a normally distributed random variable, because “neuron inputs tend to follow a normal distribution, especially with Batch Normalization” [4]. We could zero, or “drop”, the value with probability equal to the likelihood that a normal draw would be below the observed value.
There is some confusion in various blogs about whether GELU is actually stochastic in that way. Quite clearly from the original paper, it isn’t. The inspiration is stochastic, but the actual activation unit is not. GELU ends up being defined as GELU(x) = xP(X ≤ x). A picture is worth a thousand words.

We can see the overlap of blue (GELU) and orange (ReLU) lines. After all the discussion of probabilistic dropout, in the end GELU is a deterministic function of its inputs and isn’t very far off from ReLU, mostly differing in the range where inputs are slightly below 0. The authors even write that “in fact, the GELU can be viewed as a way to smooth a ReLU” [4]. GELU and ReLU asymptote to the same values at both ends, and in between they nearly overlap.
Unfortunately the GELU paper also confuses the matter a bit, adding “in addition and significantly, the GELU has a probabilistic interpretation given that it is the expectation of a stochastic regularizer” as a “notable difference” in a paragraph near the end that otherwise describes actual reasons why ReLU and GELU may have different performance [4]. Bookending the paper with probabilistic emphasis might be one reason why others have ended up misinterpreting GELU.
Is GELU an improvement?
GELU performed well on experiments in the original paper. It was adopted in the first GPT model [5]. Following that, it was adopted in BERT specifically because of successful use in GPT (“We use a gelu activation […] rather than the standard relu, following OpenAI GPT”) [6]. Keep going for several years and we end up here, with GELU in ChatGPT.
I expect that some of these model creators didn’t have time to experiment on activation functions, since fitting their LLMs is slow and extremely costly. Reasonably, those practitioners have to choose which dimensions to experiment on.
Is it possible that GELU is popular partially through imitation?
Aside from the GELU paper, I had trouble finding many recent papers that evaluated activation functions rigorously and realistically. In one study, GELU performed a bit worse than RELU on the MNIST dataset and was nearly 7 times slower in model fitting [1]. In another study, GELU and RELU performed similarly on the CIFAR datasets, with a fairly equal number of victories for both of them under different architectures [7] . Their differences were usually small relative to the standard deviations of their point estimates. Interestingly, in this second paper GELU wasn’t slower in training time than RELU. Perhaps the first paper used a hand-crafted implementation while the second seems to have used PyTorch’s implementation. Another study showed GELU slightly outperforming RELU on those and other image datasets, although RELU did better with translation [8]. They didn’t report training time or explain the stopping conditions on model building, but (amusingly) at one point they wrote that “the additional 2 GELU experiments are still training at the time of submission”. While presumably those jobs finished between 2018 and now, that at least hints that GELU ran slowly, unless GELU experiments were tacked on at the end as an afterthought.
Notably, the second of those studies showed sigmoid and tanh performing much worse on every comparison than ReLU, GELU, and a host of other modern activation units. So clearly we’ve made big progress since the sigmoid and tanh days, even if the jury is still out about whether GELU (or any specific modern activation function) is better than RELU.
Setting aside that those studies disagree in some ways, they also mostly cover image models. Even when looking at various other activation function papers, of which there are only so many that are new enough to cover GELU, many of those papers make very similar comparisons on the same datasets (e.g. MNIST, CIFAR10, CIFAR100, ImageNet). The GLU paper covers a natural language setting, in which GELU and ReLU performed similarly on a broader set of language benchmarks [9].
I’ll have to keep watching as the literature evolves, with more comparisons across more settings and domains. I’d like to find a good study of how activation functions perform on the current crop of LLM architectures. But those experiments would be more costly than experiments on relatively small image datasets, at least currently.
Why does GELU work well?
Despite the uncertainty, I feel optimistic about GELU. Success in GPT models and BERT models, among others, makes GELU one of the current champions of language models. This is true even if those researchers didn’t report other activation functions. They might have casually tested different activation functions, and even if not, GELU still worked for them.
Despite fairly small differences between ReLU and GELU, there are some advantages to GELU highlighted by its creators. The GELU is smooth at all points, including at 0. It can output both positive and negative values, which may have implications on model training and performance [2, 7]. But the GELU paper considers other differences to be more substantial. Specifically, the non-monotonicity of GELU and its non-linear curvature even for positive values. I’ll show the function again here to save you from scrolling.
In the area between -2 and 0 we see a large non-monotonic reversal. Then in the positive domain from 0 to 2, there is some variance in the slope of GELU while ReLU is absolutely constant. The authors speculate that “increased curvature and non-monotonicity may allow GELUs to more easily approximate complicated functions than can ReLUs”, which seems like a reasonable theory [4]. GELU has the benefits of ReLU, along with some other practical improvements, outweighing the cost of its more complex calculation.
Altogether, we have lots of reason to believe that GELU is a strong activation function, and since it is used for some of our most challenging ML applications, we should consider it one of the SOTA activation functions. For now, at least.
[1] Nguyen, A., Pham, K., Ngo, D.T., Ngo, T., & Pham, L.D. (2021). An Analysis of State-of-the-art Activation Functions For Supervised Deep Neural Network. 2021 International Conference on System Science and Engineering (ICSSE), 215-220.
[2] Szandała, T. (2020). Review and Comparison of Commonly Used Activation Functions for Deep Neural Networks. ArXiv, abs/2010.09458.
[3] Krizhevsky, A., Sutskever, I., & Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60, 84 - 90.
[4] Hendrycks, D., & Gimpel, K. (2016). Gaussian Error Linear Units (GELUs). arXiv: Learning.
[5] Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training.
[6] Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv, abs/1810.04805.
[7] Dubey, S.R., Singh, S.K., & Chaudhuri, B.B. (2021). Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing, 503, 92-108.
[8] Ramachandran, P., Zoph, B., & Le, Q.V. (2018). Searching for Activation Functions. ArXiv, abs/1710.05941.
[9] Shazeer, N.M. (2020). GLU Variants Improve Transformer. ArXiv, abs/2002.05202.
At least, I think so. Earlier GPT models certainly used GELU and there has been no documentation to the contrary for more recent ones.